09 技术奇点——人工智能的自我挑战
机器人颠覆人类是很多科幻故事的主题,但对于“担当身前事”的科学家来说,他们聚焦的依然是当下人工智能面对的挑战和瓶颈。而这体现的依然是人的智慧。
目前全世界数据的爆发近乎失控,要想将数据进行分类计算需要极大的革新。从根本上说,人类尚未完全适应数据化生活,正如肉身至今也没有适应大工厂机器流水线的节奏一样,这是深层矛盾的来源。
矛盾就是动力。在某些方面,我们可以看到今日的矛盾和工业革命时代有类似之处。
飞梭与珍妮机的纠缠关系就是代表。1733年,飞梭的发明使织布速度大大加快。但问题马上来了,织布需要原料——棉纱,而纺纱的速度赶不上织布,只能依靠增加纺纱工和纱锭数量来弥补。1764年,让纺纱效率成倍提高的珍妮机被发明出来,纺纱的速度终于赶上了飞梭吃原料的速度。沿着珍妮机的思路,卷轴纺纱机和走锭精纺机相继诞生,这下轮到飞梭织布速度不够了,于是又推动了水力织布机的发明。两者在技艺上交替上升,互相激发。差不多同一时候,瓦特的蒸汽机出世,蒸汽原力觉醒,纺纱和织布部门都争相引入这股泥石流。工业革命就在无数机械的同声共鸣中一往无前,生生不息。
如何跨越数据的“马尔萨斯陷阱”
今天的人工智能与数据的关系也类似飞梭与珍妮机的关系。过去,人类构思出机器学习的方法,却苦于没有足够多的数据来验证和训练。互联网大爆发终于使数据不是问题,但如何处理爆发式增长的数据又开始考验硬件能力和计算能力。
巨头的数据烦恼
最早学会享用数据“螃蟹”的勇士之举,成就了BAT等大型互联网企业。巨头都曾对如何处理海量数据有深刻体会。
阿里巴巴早期使用Oracle数据库进行数据存储。这种互联网1.0时代的数据库架构很快就难以承受电商数据的爆发式增长。阿里巴巴不得不彻底换血,重金打造和使用自己研发的数据库。
京东在2013年以前经常因访问量暴增而造成服务器瘫痪,不得不更新后台架构,用java技术取代.net技术。
中国老百姓感受最深的应该还是几年前12306网站的购票灾难。过年要回家,这是融入中国人血脉的传统。但这样一个人口大国,每到春节就会上演“数字”灾难。对于实体世界中的火车线路来说,这是运力矛盾,每个人都感受过挤在车厢中动弹不得的痛苦,没有尊严,仿佛一个个冰冷的比特。这种矛盾通过高铁建设逐渐缓解。但同样的拥挤转移到了网络上。为了方便购票,铁道部对购票系统进行信息化升级,12306网站上线。不过当时并没有料到互联网化带来的数据挑战是什么。本想方便群众购票,却首先创造了不方便——上亿人同时查询、购买车票的行为让服务器迅速卡死。很多批评声音出现,认为程序员无能,认为换上电商工程师就能解决这个问题。
但真正关键的因素还是处理能力跟不上数据发展。有人专门比较了电商网站与12306网站。“双十一”时,淘宝等电商网站虽然也承接了海量人群的下单行为,但是这些单子被分布到数量巨大的商品上,彼此之间相关度很低,计算量也被服务器分摊了。火车票则不同,全国的班次就那么多,而火车票的抢购中,每一趟火车的千余个座位很可能面临数万甚至数十万人的抢购,火力极其集中。每发生一次购买行为,出票系统不但要分析该车次所有站点的数据,还要计算数十倍于车次出票数的抢票顺序数据,并实时更新沿线车站的可售票数,可以说是牵一票而动全身。数据和计算量呈几何式增长,而且一切还都要在瞬间完成,即便不计成本地投入更多服务器也难以解决。这种难题是大电商也没有遇到过的,直到后来探索出新的计算架构和方法,才得以缓解。
BAT中最早面临大数据冲击的还有百度。“百度一下,你就知道”,全民搜索行为将海量数据发向百度服务器。日夜增长的网络信息也让百度内容爬虫疲于奔命。百度采用了预搜索和相关词搜索等方式缓解服务器遭遇的瞬时数据冲击问题。预搜索方式下,系统在搜索请求数量较低时(如凌晨)也在自动搜索并把搜索结果固化。在用户发送搜索请求时,系统就将已经整理好的结果推送过去,不需要服务器再把搜索任务跑一遍。相关词推荐也是利用系统相对空闲的时间以及功能架构清晰的数据库系统,对用户数据行为做相关性分析,比如当用户在搜索输入框输入TPP(跨太平洋伙伴关系协定)三个字母时,搜索框就会自动弹出下拉菜单提供搜索选择,比如:TPP是什么意思、TPP对中国的影响、TPP12个成员方、TPP协议等。当然,系统也会猜测少数用户表达的是“淘票票”的拼音缩写,也会列在非优先位置供用户选择。这些选项排列可谓善解人意,且能满足大多数人的需求。
在搜索结果页面下方,百度还提供了相关词搜索,比如美国新总统大笔一挥,签字退出前任费尽心机达成的TPP。这条新闻的相关搜索如图9-1所示。

图9-1 TPP相关词搜索结果
此外,搜索引擎还根据网友搜索热度排列出与TPP相关的热搜新闻,方便用户获取信息。

图9-2 与TPP相关的热搜新闻
这些都是通过对大量用户搜索的统计做到的,从而大大优化搜索体验,提升搜索速度,缓解数据处理压力。
可以说,数据引发的问题千奇百怪。数据并非均质的比特,而是和各种特殊人类活动场景相关,使得数据处理面临各种挑战。但从根本上来看,还是珍妮机与飞梭的矛盾——硬件的所有进步都会立刻被计算量和数据量吃掉。虽然硬件能力发展速度也很快,以相同成本下每18~24个月翻一番的速率增长(也称为摩尔定律)
Ian Goodfellow,Jonathon Shlens(乔纳森·舍琳)和Christian Szegedy在论文《Explaining and Harnessing Adversarial Examples》中给出了一个典型:
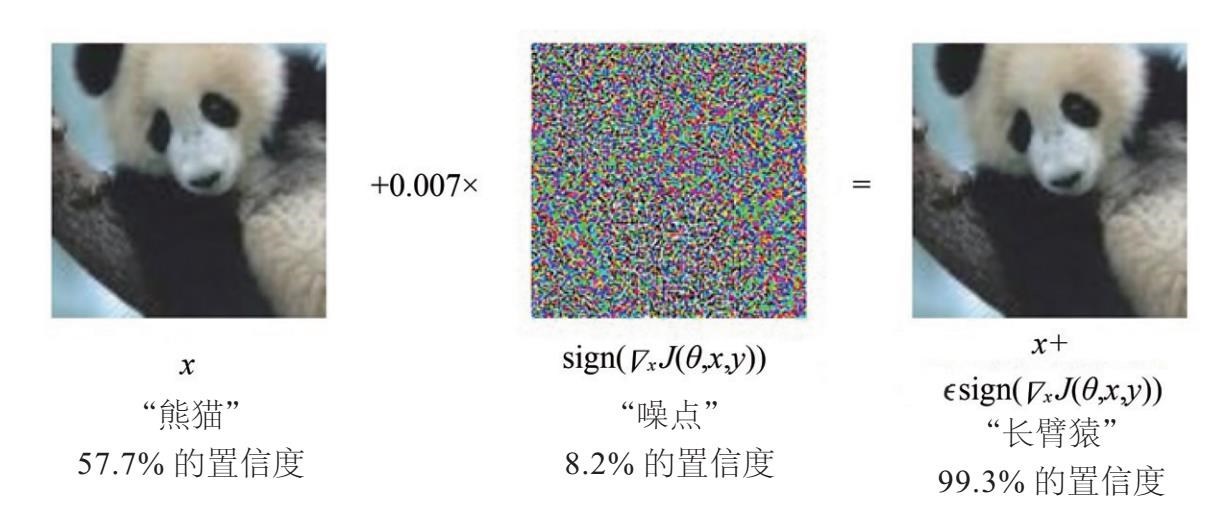
图9-5 深度学习对抗样本
资料来源:https://arxiv.org/pdf/1412.6572v3.pdf
在第一张图中,原始图像是熊猫,神经网络以57.7%的置信度判断为“熊猫”。
然后人类给图片加入微小的干扰,也就是第二张图所示的噪点。使用32位浮点值来执行修改,不会影响图像的8位表示。